Life of a stream
Introduction #
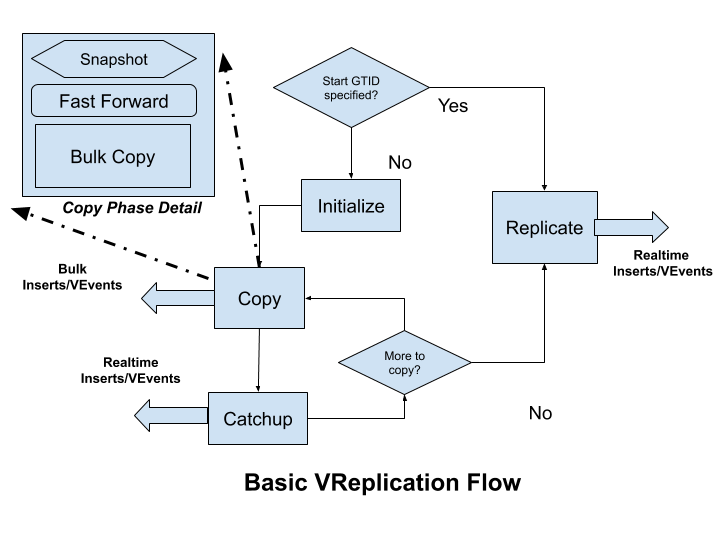
The diagram above outlines how a VReplication workflow is performed. VReplication can be asked to start from a specific GTID or from the start. When starting from a GTID the replication mode is used where it streams events from the binlog.
Full table copy #
When starting from the beginning the simple streaming done by replication can create an avalanche of events (think 10s of millions of rows). To speed things up a copy/catchup mode is initiated first: data in the tables are copied over in a consistent manner using bulk inserts. Once we have copied enough data so that we are close enough to the current position (when replication lag is low) it switches over (and stays in) the replication mode.
While we may have multiple database sources in a workflow each vstream has just one source and one target. The source is always a vttablet (and hence one mysql instance). The target could be another vttablet (resharding) or a streaming grpc response (vstream api clients).
Transformation and Filtering #
Note that for all steps the data selected from the source will only be from the list of tables specified (specified via Match). Furthermore if a Filter is specified for a table it will be applied before being sent to the target. Columns may also be transformed in the Filter’s select clause.
Source and Sink #
Each stream has two parts. The target initiates streaming by making grpc calls to the source tablet. The source sources the data connecting to mysql as a replica or using sql queries and streams it to the target. The target takes appropriate action: in case of resharding it will convert the events into CRUDs and apply it to the target database. In case of vstream clients the events are forwarded by vtgate to the client.
Note that the target always pulls the data. This ensures that there is no problems of buffer overruns that can occur if the source is pushing the data since (especially in sharding) it is possible that the application of events can be substantially cpu intensive especially in the case of bulk inserts.
Modes, in detail #
Replicate #
This is the easiest step to understand. The source stream just mimics a mysql replica and processes events as they are received. Events (after filtering and transformation) are sent to the target. Replication runs continuously with short sleeps when there are no more events to source.
Initialize #
Initialize is called at the start of the copy phase. For each table to be copied an entry is created in _vt.copy_state with a zero primary key. As each table copy is completed the related entry is deleted and when there are no more entries for this workflow the copy phase is considered complete and the workflow moves into the Replication mode.
Copy #
Copy works on one table at a time. The source selects a set of rows from the table with higher primary keys that the one copied so far using a consistent snapshot. This results in a stream of rows to be sent to the target which generates a bulk insert of these rows.
However there are a couple of factors which complicate our story::
- Each copy selects all rows until the current position of the binlog.
- Since transactions continue to be applied (presuming the database is online) the gtid positions are continuously moving forward
Consider this example.
We have two tables t1 and t2 and this is how the copy state proceeds: Each has 20 rows and we copy 10 rows at a time. (Queries are not exact but simplified for readability).
If we follow this we get:
T1: select * from t1 where pk > 0 limit 10. GTID: 100, Last PK 10
send rows to target
T2: select * from t1 where pk > 10 limit 10 GTID: 110, Last PK 20
send rows to target
Gotcha: however we see that 10 new txs have occurred since T1. Some of these can potentially modify the rows
returned from the query at T1. Hence if we just return the rows from T2 (which have only rows from pk 11 to 20)
we will have an inconsistent state on the target: the updates to rows with PK between 1 and 10 will not be present.
This means that we need to first stream the events between 100 to 110 for PK between 1 and 10 first and then do the second select:
T1: select * from t1 where pk > 0 limit 10. GTID: 100, Last PK 10
send rows to target
T2: replicate from 100 to current position (110 from previous example),
only pass events for pks 1 to 10
T3: select * from t1 where pk > 10 limit 10 GTID: 112, Last PK 20
send rows to target
Another gotcha!: Note that at T3 when we selected the pks from 11 to 20 the gtid position has moved further! This happened because of transactions that were applied between T2 and T3. So if we just applied the rows from T3 we would still have an inconsistent state, if transactions 111 and 112 affected the rows from pks 1 to 10.
This leads us to the following flow:
T1: select * from t1 where pk > 0 limit 10. GTID: 100, Last PK 10
send rows to target
T2: replicate from 100 to current position (110 from previous example),
only pass events for pks 1 to 10
T3: select * from t1 where pk > 10 limit 10 GTID: 112, Last PK 20
T4: replicate from 111 to 112
only pass events for pks 1 to 10
T5: Send rows for pks 11 to 20 to target
This flow actually works!
T1 can take a long time (due to the bulk inserts). T3 (which is just a snapshot) is quick. So the position can diverge much more at T2 than at T4. Hence we call the step in T2 as Catchup and Step T4 is called Fast Forward.
Catchup #
As detailed above the catchup phase runs between two copy phases. During the copy phase the gtid position can move significantly ahead. So we run a replicate till we come close to the current position i.e.the replication lag is small. At this point we call Copy again.
Fast forward #
During the copy phase we first take a snapshot. Then we fast forward: we run another replicate from the gtid position where we stopped the Catchup to the position of the snapshot.
Finally once we have finished copying all the tables we proceed to replicate until our job is done: for example if we have resharded and switched over the reads and writes to the new shards or when the vstream client closes its connection.